
In the last eight weeks, we've watched the agent landscape shift three times. Opus 4.7 became the default across four platforms in a single Thursday. Cognition released SWE-1.6 for free, then started taking $25B valuation calls. OpenAI launched GPT-5.5 with a coding-tuned variant a week later. Warp added Kimi, MiniMax, and Qwen in a single release and open-sourced their orchestrator the same week. If your team standardized on one agent eight weeks ago, your choice is already outdated.
Here is the thesis: locking into a single agent provider is the worst architectural decision you can make in 2026. The orchestration layer (specs, task decomposition, review workflow, evidence) has to be agent-agnostic, or it has to be rebuilt every quarter. Those are the only two options.
We've spent a year watching teams discover this the hard way. They pick a vendor, sink six months into a workflow shaped around that vendor's quirks, then watch a competitor ship something 3x better and realize the migration cost is bigger than the productivity gain. The rational choice (adopt the better tool) becomes economically irrational. That's lock-in working as designed.
This post is the field report. What's changing, why it's not slowing down, and what "agent-agnostic" means in practice when you actually have to ship.
01. The agent landscape moves faster than your procurement cycle
If you map the last sixty days of agent releases on a calendar, the density looks broken. It isn't. This is the new baseline.
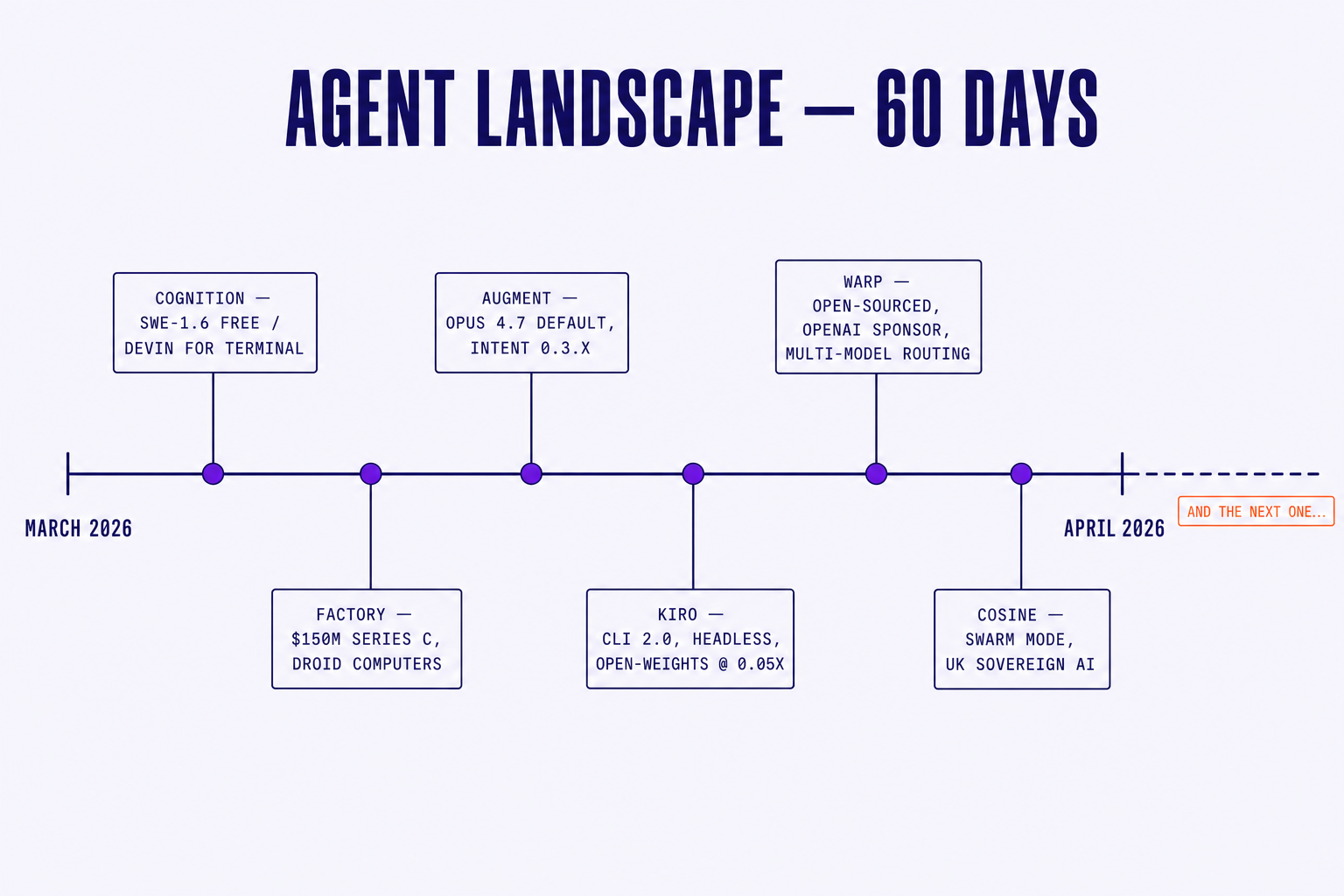
A partial list, in no particular order:
- Cognition. SWE-1.6 went free. Devin for terminal launched. Windsurf got bundled in. The company is fielding $25B valuation talks while shipping weekly.
- 8090. Raised an extension at a $1.2B valuation. Shipped a vertically integrated multi-agent runtime as a new product surface. Enterprise tier with proprietary model routing.
- Augment. Opus 4.7 became the default. Intent 0.3.x is iterating roughly every ten days, with breaking changes in spec format twice in March alone.
- Kiro. CLI 2.0 with a headless mode for CI. Open-weight models priced at 0.05x the credits of the frontier tier. Specs format changed under the hood.
- Warp. Open-sourced the terminal. OpenAI sponsored the launch. Open-source model routing is now first-class. Kimi, MiniMax, Qwen added in one drop.
- Cosine. Swarm mode for parallel agents. UK sovereign AI deal. Genie 3 with a context-handling rewrite.
Now ask yourself how long your last vendor evaluation took. Four weeks? Six? By the time procurement signs the MSA, the platform you evaluated is two product cycles behind itself. The RFP answers were correct when you wrote them and wrong by the time you signed them.
This isn't a temporary spike. Model improvement is accelerating, not decelerating, and every platform is fighting for the moat that frontier-model access used to provide. The moat is gone. What's left is workflow, distribution, and pricing, three things that change weekly.
The practical consequence: any team that bets the workflow on a specific agent is betting against the market. You don't have to predict who wins. You have to assume the answer changes, and design for that.
02. The lock-in trap is subtle, and that's why it works
Every agent vendor wants you locked in. They would not say it that way. They would say "deeply integrated", "first-class", "native experience". The mechanism is the same.
8090 builds and ships their own agents on their own runtime. Kiro defaults to AWS-hosted models and bills against AWS credits. Cognition bundles SWE-1.6 with Windsurf and the Windsurf-shaped editor experience. Cosine's Genie agents are proprietary, run on Cosine infrastructure, and produce Cosine-shaped artifacts. These are good products. They are also lock-in surfaces.
And the lock-in isn't really the agent. That's the part teams notice and feel ok about: "we can swap models". The lock-in is everything around the agent:
- The spec format the agent expects (Kiro's
.kiro/specs/, Cursor's rules files, Augment's intent schema) - The task structure the agent decomposes work into
- The review workflow built around that agent's diff and trace outputs
- The analytics and metrics keyed off that agent's telemetry
- The hooks and skills written against that agent's plugin API
Once your team's processes are shaped around one vendor's orchestration, switching costs compound. It isn't the model swap that hurts. It's the six months of specs, the eighteen hooks, the custom slash commands, the analytics dashboard built on the wrong telemetry schema.
The agent is the cheapest part to swap. The workflow built around the agent is the expensive part. Lock-in lives in the workflow, which is exactly where vendors put it.
A real scenario, anonymized but composite. A team adopts Kiro. Six months in, they have ~120 specs in .kiro/specs/ format, a dozen Kiro-specific hooks, fifteen slash commands, a PR review template that assumes Kiro-shaped diffs. Then a new agent ships, and on their codebase it benchmarks 3x better at the kind of refactoring work they do most. Switching means rewriting every spec, every hook, every skill, and retraining the team on a new mental model. They price the migration. They don't switch.
Multiply that across a few hundred teams and you get the current state of the market: most teams are running on a stack they would not pick today, because the cost of leaving is higher than the cost of staying suboptimal. This is how good-enough becomes permanent. It's also how vendors with mediocre products keep enterprise customers for years.
"We didn't pick our agent. We picked the agent we used eighteen months ago, and never had a quarter quiet enough to switch." VP of Engineering, mid-market SaaS
The trap isn't the first decision. It's the second, third, and fourth one: the ones that look like productivity wins and are actually moat construction by your vendor, paid for by your team.
03. What agent-agnostic actually means
"Agent-agnostic" is the kind of phrase that gets cheap fast. Every vendor claims it. Most of them mean "we support multiple models behind our API". That's table-stakes multi-model routing, and it doesn't solve the lock-in problem. It just hides it one layer deeper.
Agent-agnostic, the way we mean it, has a stricter definition: the orchestration layer, specs, task decomposition, and review workflows are independent of the executing agent. You can swap the agent without rewriting any of the four.
Three concrete requirements fall out of that.
1. Specs are portable. The spec is the contract between intent and execution. It should be written in a format any agent can consume: plain Markdown with structured sections, evidence requirements, and acceptance criteria. Not a vendor-specific schema. If your specs only run on one platform, they aren't specs. They're configuration files for that platform, dressed up.
2. Execution is pluggable. Swap agents per task, per project, per team, without changing the workflow. Claude Code for the dense backend refactor. Codex for the frontend component pass. OpenHands for the long-running migration script. A smaller, cheaper open-weight model for the ten thousand boilerplate edits. The orchestration layer doesn't care which agent ran the task. It cares whether the spec was met.
3. Review is evidence-based, not agent-shaped. The review step checks spec compliance (diff against intent, evidence suite passed, acceptance criteria green), not vendor-specific outputs like "Claude's plan trace looks reasonable". If your review process depends on a particular agent's introspection format, you've embedded the vendor in the most expensive part of your workflow.
We call the practical version of this BYOAI (bring your own AI). A Steerdev customer can wire Claude Code to their backend specs, Codex to their frontend specs, and a self-hosted OpenHands cluster to their migration specs, all in one project. The coordination layer routes tasks, gathers evidence, and runs reviews against the spec. Agents are interchangeable. Specs and evidence are not.
The test for whether your stack is actually agent-agnostic is simple. If a better agent shipped tomorrow, how long would it take to put it on the same workflow? If the answer is "a sprint", you're fine. If the answer is "a quarter", you're locked in and don't know it yet.
04. The best agent today won't be the best agent tomorrow
Look at the historical pattern. In 2024, Copilot was the dominant developer AI surface and the conversation was over. In 2025, Cursor and Windsurf surged past it, and the conversation was over again. By mid-2025, Claude Code and Codex had pulled most of the serious agentic work. Now, in 2026, we have Devin, Kiro agents, Augment Intent, OpenHands, Cosine Genie, and a dozen open-source alternatives all shipping weekly, and the conversation refuses to stay over.
No single winner has lasted more than twelve months. There is no reason to believe the next twelve will be different. The underlying models keep getting better, and the surface that exposes them keeps getting reshaped. That's a feature of the market, not a bug.
The teams that win are not the teams that bet correctly on the current leader. They are the teams that built infrastructure capable of adopting the new leader the week it ships. Opportunistic about execution, consistent about process. That combination is what compounds.
Put another way: the question "which agent should we standardize on?" is the wrong question. It assumes a stable answer in a market that has not produced one. The right question is "what does our workflow have to look like so that the answer can change without it costing us a quarter?". That's the question agent-agnostic infrastructure exists to answer.
05. The temporary thing and the permanent thing
The agent you use today is a temporary choice. The coordination layer you build is a permanent investment. Make sure the permanent thing doesn't depend on the temporary thing.
We built Steerdev on this principle, and we've watched our own customers prove it. Teams that started on one agent eight months ago are routinely running on a different one today, with the same specs, the same review workflow, the same analytics. Nothing they built around the agent had to be rewritten. That's not because we picked the right agent. It's because the workflow doesn't depend on the agent at all.
Agents come and go. The model leaderboard is going to keep moving. There is no version of the next two years where you pick one platform and ride it without surprises. But the workflow that makes your team effective with any agent, that is what compounds. That is what survives the next Opus release, the next OpenAI launch, the next $25B valuation, the next open-source rewrite of someone's terminal.
Thanks for reading this blog! Build the permanent thing carefully. Swap the temporary thing freely. Next: how we're replacing our ERP with AI agents →
References
- GitHub Changelog, Claude Opus 4.7 is generally available, Apr 2026.
- Cognition AI, Introducing SWE 1.6: Improving Model UX, Apr 2026.
- Warp, Warp is now open-source, Apr 2026.
- Cosine, Parallelising Software Development: The Next Leap.


