
Monday, 9:14am. Five engineers each kick off two or three coding agents. Claude Code on one repo, Codex on another, an OpenHands agent running an end-to-end refactor in a third. By Wednesday lunch, three pull requests collide on the same auth middleware. Two agents independently rewrote the same payment module from different specs. Nobody can answer the simple question: which version of the requirement drove which branch?
The industry spent two years answering "can agents write code?". The answer is yes, comfortably. Windsurf 2.0 is in production at scale. Cursor's parallel agents close hundreds of thousands of tasks a day. Kiro ships with a million-token context window and a real opinion about specs. The agents are good.
The question nobody has answered is the next one: can a team of humans and agents ship together without chaos? That is not an agent problem. It is a coordination problem. And the gap is widening every month.
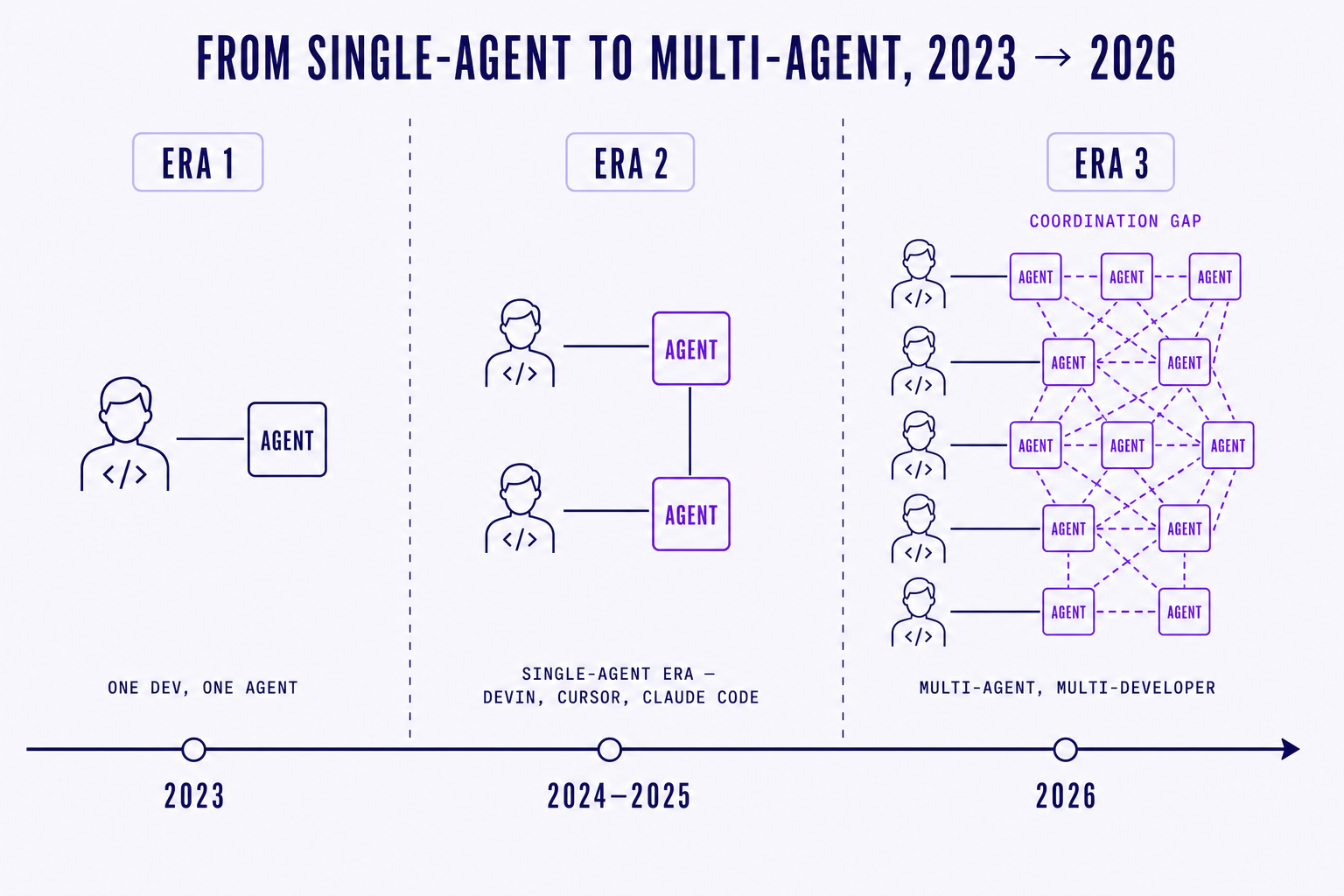
01. The individual agent era is over
2024 and 2025 were the single-agent era. One developer, one IDE, one assistant. Devin made the demos. Cursor and Claude Code made the daily driver. The unit of analysis was the engineer with a copilot, and the productivity story was "I ship faster on my own."
2026 looks different. Warp ships parallel agents by default. Augment Intent runs background work across a repo while you keep typing. Cursor's background agents spin up fleets that work overnight. Anthropic's own Claude Code now happily runs three or four sessions in tandem on a serious engineer's laptop. The unit of analysis is no longer the developer with an assistant. It is a team of developers, each running multiple agents, all touching the same codebase.
The agents got good. The teamwork didn't.
We have seen this pattern before. Before Git, developers could write code but couldn't merge it without stepping on each other. Before continuous integration, they could build but couldn't deploy together without a war room. Each generation of tooling unlocked individual capability long before it unlocked team capability. The team layer always lagged.
We are in the pre-coordination era of AI coding. The individual capability is here. The team layer is not.
The symptoms are everywhere if you look. Team leads tell us their agents-per-engineer ratio jumped from one to three in a single quarter. CI pipelines that used to handle ten pull requests a day now process forty, half of them generated overnight. Code review queues balloon. Merge conflicts compound. The dashboards that worked at one-agent-per-human stop working at six.
The most telling shift is in how engineers describe their week. A year ago you would hear "I shipped this feature with Cursor, it was great." Now you hear "we had four agents going on the auth refactor, two on the new checkout, and somewhere in there we lost track of which branch was canonical." The language has moved from singular to plural without anyone noticing. The tooling has not.
What was an individual productivity story in 2025 has become a team throughput problem in 2026. The agents are not the bottleneck. The human-machine choreography around them is. And choreography, unlike model quality, does not improve by itself with the next release.
02. Three coordination failures we see every week
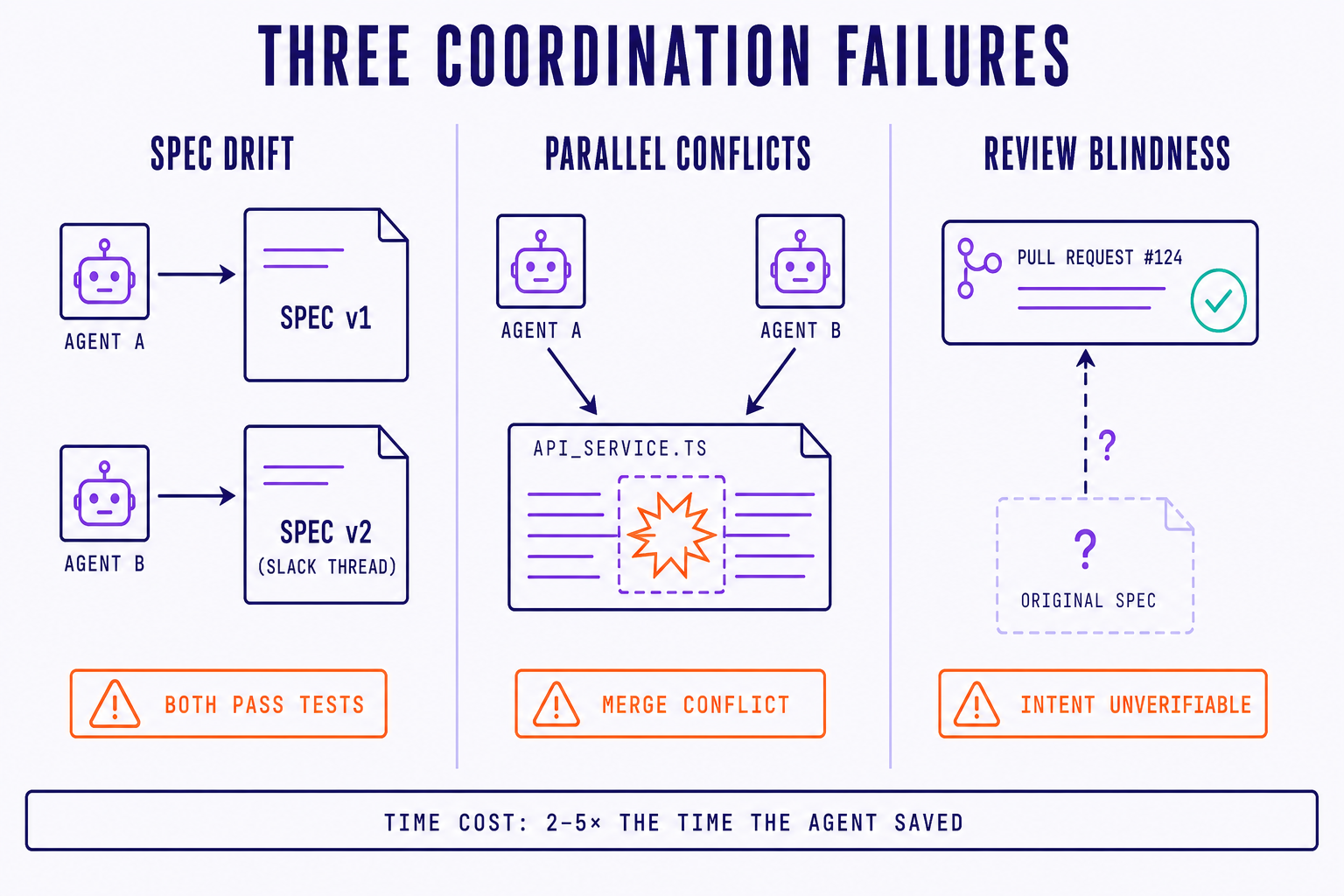
We look at a lot of teams adopting multi-agent workflows. Three failure modes show up so often we have started naming them.
The first is spec drift. Two agents start work on the same feature, but from different snapshots of the requirement. One was kicked off Monday, when the spec said "users see recommendations on the homepage." The other started Thursday, after the PM tightened the wording to "logged-in users see personalized recommendations on the homepage, ranked by recency." Both agents pass their tests. Neither pull request is actually what the PM wanted, because neither matches the current spec. The team rediscovers this in review, after eight hours of agent work and two hours of human cleanup.
The second is parallel conflicts. Four agents take on four tasks that look independent on a kanban board. Underneath, they all touch auth/middleware.ts, lib/db.ts, and the same migrations folder. The first pull request lands clean. The second rebases with three small conflicts. The third gives up and the engineer manually rewrites half of it. The fourth gets abandoned. The agents did the work. The human re-did it. The net productivity gain is negative for that wave.
The third is review blindness. An agent ships a 600-line pull request. The diff looks clean. Tests pass. The description is nicely formatted. The reviewer cannot trace any of it back to a specific acceptance criterion, because there is no link between the PR and the spec it was meant to satisfy. So review becomes either a rubber stamp ("looks fine, LGTM") or a re-derivation of intent from the code itself, which takes longer than writing it would have. Either way, the review loop has lost its teeth.
Each of these failures is quietly expensive. An agent that saves you four hours of typing but costs you ten hours of merge work, spec reconciliation, and review re-derivation is not saving you four hours. It is costing you six. Teams we work with consistently report that uncoordinated multi-agent runs cost two to five times the time the agents nominally saved, once you count cleanup. The productivity story flips upside down.
A quick back-of-the-envelope makes the shape of the problem obvious. Say a five-engineer team runs three agents each, fifteen agents in flight on a given day. Each agent ships, on average, an hour of useful diff. That is fifteen hours of nominal output. Now apply realistic friction: 20% of the runs hit spec drift and have to be redone, 15% collide on shared files and need manual resolution, 25% land but get rubber-stamped through review and surface as bugs in the next sprint. The net useful output is closer to seven hours, and the cleanup tax falls on the senior engineers who were supposed to be designing systems, not playing janitor for the fleet.
This is the part founders and engineering leaders feel before they can articulate it. The team is doing more, but shipping less of value. The agents are technically working, but the team metrics keep slipping. The gap between activity and progress widens every week. That gap is the coordination tax.
"We measured it. Our agents wrote 40% more code last quarter. Our engineers spent 60% more time in review and merge. That is not the trade we signed up for." VP Engineering, mid-market SaaS company
The failure is not in any single agent. Each agent did exactly what it was asked. The failure is in the system around them, the absence of a layer that knows what is being asked, by whom, against which requirement, and on top of which other in-flight work.
03. Why better agents won't fix this
The natural reflex from inside a model lab is to ship a smarter agent. Better planning. Longer context. More careful self-review. This is good work and we are glad people are doing it. It will not solve the coordination problem.
Coordination is not an intelligence problem. It is an infrastructure problem.
Think about traffic. Faster cars do not reduce congestion in a city. You can give every driver a Ferrari and the rush hour will get worse, not better. What reduces congestion is roads, lights, lane markings, signage, and a shared rulebook everyone agrees to follow. Infrastructure is what lets independent agents (drivers) make local decisions that compose into global throughput.
Agents are the cars. Coordination is the road network. You cannot patch a missing road network by upgrading the engine.
8090 reads the diagnosis correctly. Their pitch is essentially "the multi-agent era needs a coordination substrate, and we are building it." We agree on the diagnosis. We disagree on the answer, because their version of the substrate is a vertically integrated stack: their agents, their workflow, their lock-in. That is coherent for them and probably good for some buyers. It is the wrong shape for the rest of the market.
The coordination layer has to be open. Teams already use Claude Code, Cursor, Codex, Devin, OpenHands, Aider, and three more they will adopt next quarter. An infrastructure layer that only works if you give up your agents is not infrastructure. It is a walled garden with extra steps.
The right answer is an open coordination layer that sits above whichever agents your team already uses. It should not care which model wrote the diff, as long as the diff is traceable to a spec, dependency-checked against in-flight work, and reviewable against acceptance criteria. That is what infrastructure looks like when it works: invisible most of the time, indispensable the rest.
We have been here before, by the way. Git was not a smarter editor. It was the missing layer that let many editors compose into a coherent codebase. CI was not a smarter compiler. It was the missing layer that let many commits compose into a coherent release. Each generation of team-scale infrastructure was open, agnostic to what sat above and below it, and ruthless about a single contract: traceable changes, dependency-aware integration, evidence before promotion. The coordination layer for agents will look the same in shape, even if the surface looks new.
04. What coordination infrastructure actually looks like
It is tempting to imagine the answer is "Jira with AI sprinkled on top." It is not. Project management tools were built for a world where humans were the unit of work. The coordination layer for multi-agent teams has to be built for a world where the unit of work is a spec executed by some mix of humans and agents in parallel.
Three things have to be true for it to work.
First, specs that agents can read and humans can review. Not free-text tickets. Not chat transcripts. Structured specifications with versioned acceptance criteria, the kind a human can edit in a normal review flow and an agent can ingest as a deterministic input. When the spec changes, every in-flight task linked to it sees the change. Drift becomes visible instead of silent.
Second, dependency-aware task decomposition. Before agents start, the system should understand which files, modules, and tests each task is likely to touch, and schedule the work in waves that avoid collisions. If two tasks both rewrite the auth middleware, they do not run in parallel. They run in sequence, or one of them gets re-scoped. Parallel conflicts stop being something you discover at merge time and start being something you prevent at plan time.
Third, evidence-based review that traces every pull request to its spec. The review interface should not show you a 600-line diff in isolation. It should show you the diff next to the acceptance criteria it was meant to satisfy, the test runs that exercise those criteria, and the spec version that was authoritative when the agent started. Review goes from "does this look ok" to "does this satisfy the contract." Rubber stamps become impossible.
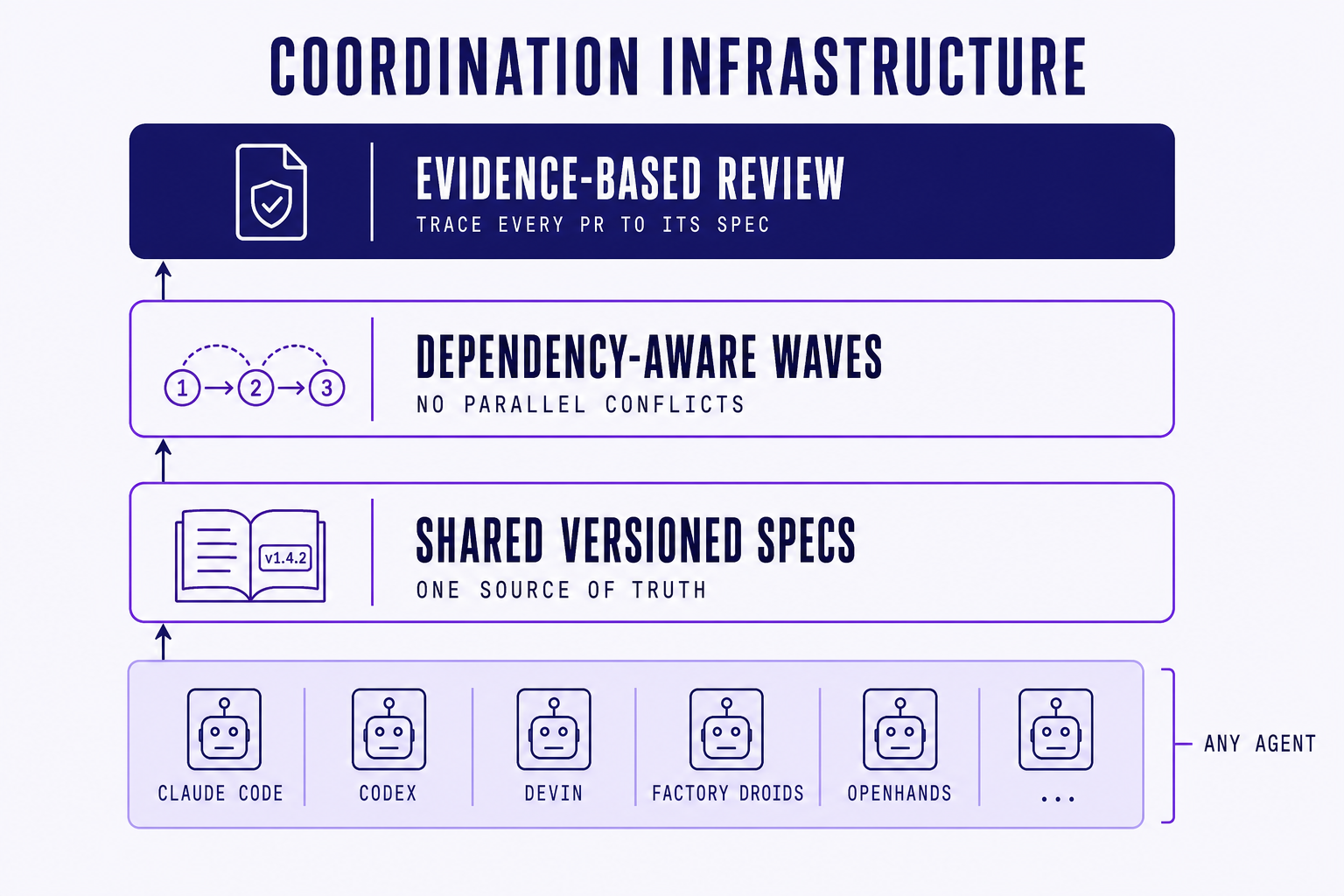
This is the shape of what we are building at Steerdev, and we will go deeper on each layer in the posts that follow. The design principle that ties it together is simple and worth stating directly: agent-agnostic by default. Claude Code, Codex, Devin, OpenHands, Aider, and whatever ships next quarter all plug in. Teams keep the agents they already trust. The coordination layer is the part that was missing.
05. Monday morning, with infrastructure
Go back to that Monday morning. Five engineers, each with two or three agents queued up.
The difference is not that the agents are smarter. It is that the system around them is no longer empty. Specs are versioned and shared, so every agent works against the same current requirement. Tasks are decomposed with dependency awareness, so the four parallel runs land in two clean waves instead of one tangled mess. Every pull request opens with the spec it satisfies, the criteria it covers, and the evidence it produced. Wednesday morning is a clean merge train, not a war room.
What shifts, when this works, is where the bottleneck lives. It stops being "writing the code." That part is cheap now. It becomes "knowing what to write, and getting the team to agree on it before five agents pour energy into the wrong thing." That is a different kind of work. It is closer to product thinking than to engineering throughput. And it is the part nobody has built proper tools for yet.
The teams that figure this out first will not be the ones with the most agents, or the most expensive models, or the loudest demos. They will be the ones whose specs are sharp, whose dependencies are visible, and whose reviews trace back to intent. Coordination, not horsepower, is the next competitive edge.
Thanks for reading this blog! We will spend the next several posts on exactly this. The next one goes deep on why the spec, not the code, is the real product of an agent-driven team, and what that means for how you write and review them. If any of the failure modes above sound familiar, follow along. We are figuring this out in the open, and we would rather compare notes than ship in silence.
References
- Cursor, New Coding Model and Agent Interface (Cursor 2.0), native parallel agents, up to 8 concurrent worktrees per prompt.
- Kiro, Bring engineering rigor to agentic development, spec-driven IDE and CLI from AWS.
- Augment Code, Intent: A workspace for agent orchestration, multi-agent execution against a single living spec.
- Anthropic, Claude Code, the CLI agent referenced throughout this series.


