
We had the problem every growing company has. Internal operations held together by spreadsheets, a half-configured ERP nobody fully trusted, a Notion database for projects, and an alarming amount of tribal knowledge in the heads of two or three people. Invoicing took hours every month. Project tracking was split across three tools. Resource allocation was a PM with a spreadsheet and good instincts. Reporting always lagged the reality on the ground.
We could have bought another SaaS. Another ERP tier. Another integration layer to staple it all together. Instead we did something that, on paper, sounds reckless: we used Steerdev (the platform we sell to other teams) to build our own internal operational system from scratch. Not because it was the easy path. Because the only honest way to know where your product breaks is to use it for something with real stakes, on a real deadline, when nobody is watching.
The thesis was simple. If our methodology is what we say it is (spec-first, agent-agnostic, evidence-based review), then we should be able to ship a custom operational system in weeks, not months. And if we can't, we'd rather find that out on ourselves than on a customer.
This is the post about that project. What we built, where things broke, and what we changed in our own product because of it. It is not the cleaned-up version. It is the version with the bruises still visible, because the bruises are the part you actually learn from.
01. The mess we started with
It helps to be honest about the starting point. Here is what our "operations stack" actually looked like in March:
- Invoicing. An Excel template forked once per client, manually filled, copy-pasted into a PDF, sent over email. One teammate spent roughly 24 hours a month on it. Errors were not rare: wrong tax rates, stale rates from old contracts, missed line items.
- Project tracking. Linear for engineering work, Notion for client-facing milestones, a separate Google Sheet that the PMs used as the "real" source of truth. When leadership asked "how is project X doing?" the answer depended on which tool you opened first.
- Resource allocation. A single PM, a single spreadsheet, and a lot of institutional memory. It worked, in the sense that the trains mostly ran on time. It did not work in the sense that nobody else could read the spreadsheet, and the PM couldn't take a real vacation.
- Reporting. Assembled by hand at the end of each month from the other three sources. Always lagging. Never fully trusted. Nobody made a decision off it without double-checking the underlying data.
We looked seriously at off-the-shelf ERPs. The honest reasons we didn't buy one were not romantic. They were too rigid for a company that changes shape every quarter: new offerings, new client structures, new contract types. They were too expensive to customize, and the customization itself would have required a vendor we didn't want to depend on. And they were too slow to adapt: by the time the configuration was right, our process had moved on.
We are builders. We know what we need. So we made a decision that, in retrospect, was the entire point: treat this like a client project. Spec it. Decompose it. Run agents in parallel. Review with evidence. If our methodology works, we should have a custom operational system in weeks. If it doesn't, we should know exactly where it doesn't.
The constraint we set on ourselves was important. No shortcuts. No "we'll fix it manually after the agent finishes." Every change goes through the same loop our customers run: spec, plan, parallel agents, evidence-based review, merge. If a step felt awkward, we wouldn't route around it. We'd note it down and fix the platform.
02. The spec phase
The spec phase was easier and harder than we expected.
Easier, because we knew the requirements. There were no discovery meetings. No stakeholder interviews. No "let me get back to you on that" loops. When we sat down to write the invoicing module spec, we already knew every edge case, every contract variant, every line item we'd ever argued about. The domain expertise was sitting in the room.
Harder, because we knew the requirements. We over-specified. Badly. Our first invoicing spec had 47 individual requirements, including things like "the line item description must use the same casing as the contract clause" and "the PDF footer must left-align if the client is in the EU and right-align otherwise." These were things that were true. They were not things a spec needed to say.
What happened when we ran agents against that first spec was instructive. They produced exactly what we asked for: a module that did all 47 things, none of them well, with code so prescriptive it was difficult to extend. There was no room for an elegant solution because we had specified the inelegant one in advance.
We threw out the first spec and rewrote it to twelve requirements with clear acceptance criteria. The difference looked like this:

The v2 version read closer to a contract than a recipe:
# invoicing.module: spec v2 (excerpt)
intent: "generate accurate, audit-trail-backed invoices
from project + contract data, with no manual editing."
requirement r3 {
what: "tax rates must reflect the contract in force on the
invoice period, not the contract in force on issue date."
accept: evidence.test("billing/tax-rate-historical")
rationale: "we re-billed three clients in 2025 because of this exact bug."
}
The rewrite produced better code on the first run. Cleaner abstractions, fewer special-cases, an actually-extensible module. The agent had room to make decisions about how, because we had only constrained what. And when we later wanted to change one of those hows (for instance, swapping the PDF renderer) the change was a small, contained diff, not a forty-line patch through a prescriptive spec.
A good spec constrains what, not how. If you find yourself writing implementation details, you are doing the agent's job for it, and worse than the agent will. Spec the intent and the acceptance criteria. Trust the agent with the rest.
This lesson is now baked into how we coach our customers. Every team we onboard over-specifies on their first project. We used to gently warn them. Now we tell them directly: throw your first spec out, rewrite it with half the words, and check whether each requirement is about intent or implementation. If it's implementation, it doesn't belong.
03. The build phase
With revised specs in hand, we decomposed into four modules: invoicing, project tracker, resource allocator, reporting dashboard. Then we mapped dependencies. Invoicing depended on contracts (already in the system) and a thin "projects" data model. Project tracker depended on the same projects model plus user data. Resource allocator depended on project tracker. Reporting depended on all three.
We picked agents per task, not per project. Claude Code drove most of the backend API work (long contexts, careful refactors, good at the API-contract-design end of the spectrum). Codex handled frontend components, where rapid iteration on JSX and styling paid off. OpenHands ran the database migrations, where its sandboxed execution model fit how we wanted to verify schema changes before merging. This is what we mean when we say Steerdev is agent-agnostic in practice: the orchestration layer doesn't care which model produced the diff, as long as the diff passes the evidence suite.
Four agents ran simultaneously across three modules during the middle waves. We avoided conflicts by sequencing dependencies in the orchestration plan rather than by people:
# the actual wave plan we ran
wave 1 - foundations {
spec: "specs/foundations/{auth,projects,contracts}.md"
agents: [claude.opus, openhands]
verify: evidence.suite("foundations")
}
wave 2 - modules (parallel) {
spec: "specs/{invoicing,tracker,allocator}.md"
depends: [wave 1]
agents: [claude.opus × 2, codex.gpt, openhands]
verify: evidence.suite("modules")
}
wave 3 - dashboard {
spec: "specs/reporting.md"
depends: [wave 2]
agents: [claude.opus, codex.gpt]
verify: evidence.suite("reporting")
}
The most interesting moment in the build phase wasn't the speed. It was a mistake. One of the wave-2 agents working on the resource allocator made an assumption about how the project tracker exposed "active project" status: it assumed a boolean, but the tracker actually used an enum with three states. Spec traceability caught it in review: the allocator's PR referenced the tracker's spec section, the reviewer cross-checked, the conflict surfaced before merge. Exactly where we want failures to happen, and exactly the kind of cross-module mismatch that used to live in production for weeks before anyone noticed.
The surprise of the build phase was the reporting dashboard. We expected it to be the simplest module (read data, render charts). It turned out to be the longest. Not because of code complexity, but because its spec required well-formed data from all three other modules. If the invoicing module was still firming up its line-item schema, the dashboard couldn't render the revenue breakdown. Our dependency graph correctly sequenced reporting into the final wave, but the lesson was real: in a system where reads cross every module, your reporting layer is a dependency vacuum. Spec it last, with discipline.
Real timings, not rounded:
- Spec phase: 4 working days
- Wave 1 (foundations): 2 working days
- Wave 2 (modules in parallel): 5 working days
- Wave 3 (reporting): 3 working days
- Integration and evidence review: 2 working days
Total: about 16 working days from blank page to production. Roughly four engineers' worth of supervisory attention, spread across two of us, plus the agents.
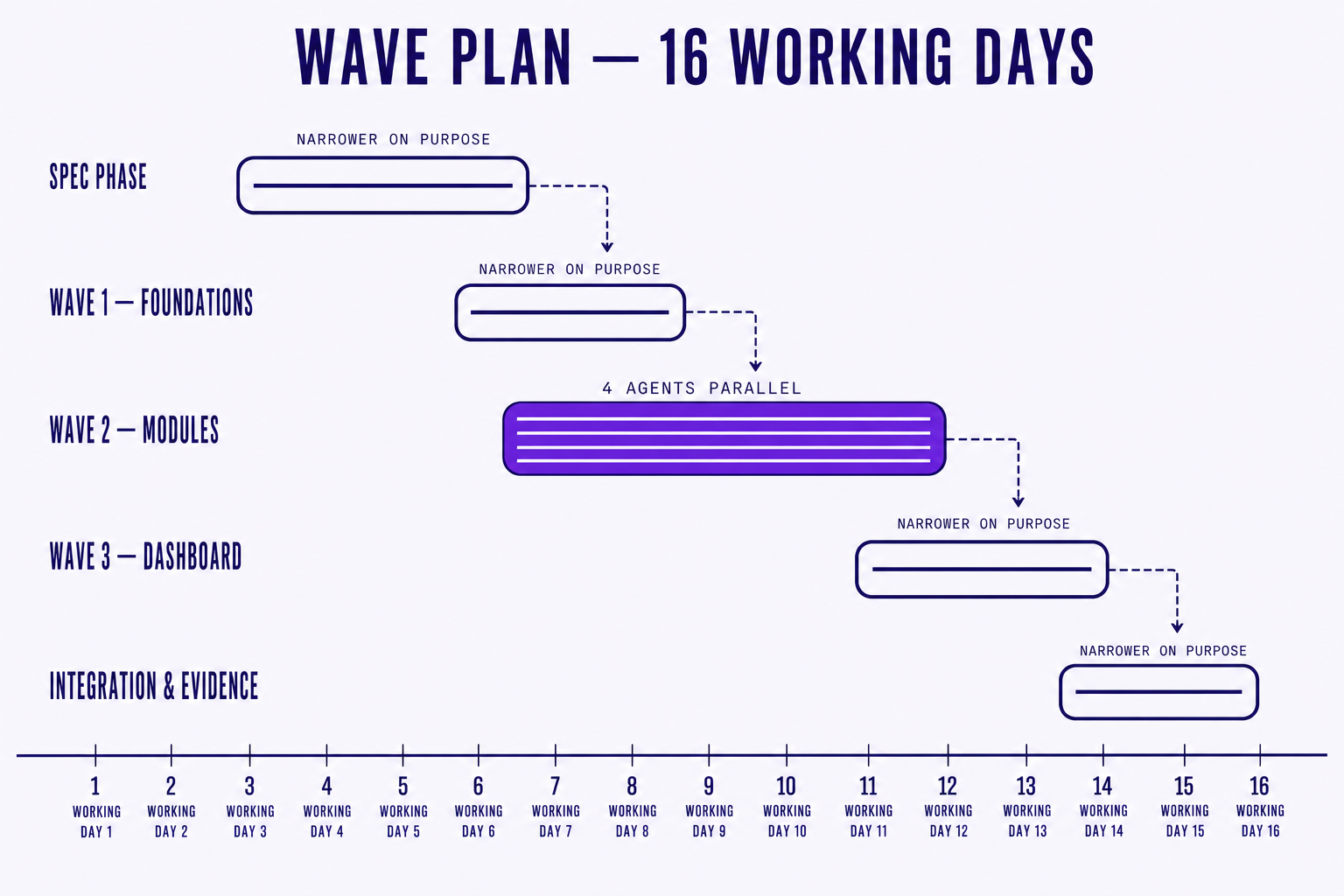
Worth naming what we did not do. We did not run all four agents from day one, as the foundations had to land first, otherwise the parallel work in wave 2 would have stepped on shared types and migrations. We did not try to make the dashboard a "first-class" early module (the temptation to build the demo-friendly screen first is real, and we resisted it). And we did not chase a fancy CI pipeline before we had a single passing module. The scaffolding stayed boring on purpose, so the interesting work could move fast.
04. Where things broke
No methodology is perfect. Ours certainly isn't. The most useful part of this entire project, from a product standpoint, was the catalog of things that went wrong. Three failures stand out.
Failure 1: context window limits. Midway through wave 2, the agent working on the project tracker module lost coherence on a large refactor. The spec was long, the existing code was long, and somewhere between reading the spec and writing the diff, the agent dropped a constraint that mattered (specifically, soft-delete semantics on archived projects). The resulting PR looked correct in isolation. It failed evidence in integration. The underlying cause: a spec too large for the working context, asking for a change that touched too many files at once.
What we changed: we now require specs above a threshold to be decomposed into self-contained units, each runnable on its own evidence suite. This is now a built-in step in the Steerdev planner. If a spec exceeds the threshold, the planner refuses to schedule it without a decomposition pass. It's annoying when you know what you're doing. It has prevented exactly this class of failure four times since.
Failure 2: cross-module integration specs were underspecified. We specified each module independently. We did not adequately spec the interfaces between them. API contracts were implied from the data models, not stated explicitly. On two occasions, two agents working on adjacent modules built incompatible interfaces: one expected a flat user object, the other passed a nested one with permissions inlined. Caught in review, but it cost a rework cycle.
What we changed: we added an "interface contract" section to the spec template. It lives next to the requirements, names every cross-module call, and pins the shape on both sides. The customer teams adopting Steerdev now have this as a defaulted section in the spec scaffold. It would have saved us a day. It has probably saved them more.
Failure 3: review fatigue. When four agents produce twelve PRs in a day, the review burden is real. You cannot meaningfully read every line of every PR. And if you try, you end up rubber-stamping the boring ones to save energy for the interesting ones, which is the worst possible failure mode.
What we changed: we built review prioritization into the dashboard. Critical-path PRs (the ones blocking the next wave) bubble to the top. Non-critical refactors get queued lower. And we leaned harder on spec-to-PR traceability: if the PR references a spec section, the evidence suite passes, and the diff stays inside the section's scope, the reviewer reads the delta against intent rather than the lines against style. This was already a Steerdev feature. Dogfooding made us actually use it.
"I used to think review was about reading every line. Once we had four agents shipping at once, I had to learn to read the spec and the evidence, and trust the diff if those two agreed." PM at Steerdev, week three of the build
Each of these failures fed back into the product. Context-aware planner thresholds. Interface contract templates. Review prioritization. They exist in shipping Steerdev today because we tripped over them ourselves. That is the actual return on dogfooding: you ship the fixes the next customer would have asked for, before they have to ask.
05. The results
We shipped a custom operational system that handles invoicing, project tracking, resource allocation, and reporting. It has been running in production for about six weeks at the time of this post. It is not perfect. It is, importantly, ours.
The numbers, as concretely as we can put them:
- Time from spec to production: 16 working days
- Hours saved per month on invoicing alone: roughly 24, and the error rate on invoices is now near zero where it used to be a recurring annoyance
- Project tracking fragmentation: from three tools to one, with a single source of truth that leadership actually opens
- Agent utilization across the project: four agents ran 38 parallel tasks across the four modules
The qualitative outcomes matter as much as the numbers. The team trusts the system because they built it with a process they understand. Every feature traces to a spec. Every spec has a rationale written next to it. When something needs changing, the spec tells you why it was built the way it was, not just what it does. That is the difference between an internal tool that calcifies and one that keeps adapting.
We should also be honest about what is not great. The reporting module still needs work. Some of the dashboards are slow on month-boundary queries because we under-specified caching. The resource allocator is good, not great. It handles 80% of cases cleanly and punts on the long tail in a way that requires manual intervention more often than we'd like. We will keep using our own platform to improve it. That's the point of dogfooding: it doesn't end at v1.
We are also watching how the system ages. An internal tool that ships in 16 days is not the same thing as one that survives a year of contract changes, new client types, and a finance team that wants its third report variant. The next test is whether the spec-rationale layer keeps the system legible as it grows. So far it does. Ask us again in six months.
06. What it taught us
The real test of a methodology isn't a demo. It isn't a benchmark. It isn't a polished case study with a Fortune 500 logo at the top. It is whether you would use it yourself, with real stakes, when nobody is watching.
We did. It worked. Not perfectly. But the failures were as valuable as the successes: they showed us exactly where our own product needed to improve, and we shipped those improvements within the same project. The ERP replacement is now our most honest reference implementation. Messy, real, exactly the kind of project most teams face. Not a greenfield startup demo. A practical system that replaces something that kind of worked with something that actually works.
Thanks for reading this blog! If you are evaluating whether spec-driven orchestration handles a real project, or you are thinking about using Steerdev for your own internal tooling, get in touch. We will show you the actual specs. The actual PRs. The actual review queue. Warts and all. That is, after all, the whole reason we built it on ourselves first. Start a conversation → Or keep reading: why we built our own harness →
References
- Anthropic, Claude Code, used for the backend API waves.
- OpenHands, The Open Platform for Cloud Coding Agents, used for sandboxed migration runs.


