
We tried very hard not to build a harness.
For nine months we tried to live on top of someone else's. Claude Code's harness was beautiful. Cursor's was polished. Devin's, Kiro's, and a handful of others in the same neighborhood, each of them a serious piece of engineering, well-funded, ahead of anything we could ship in a quarter. Every time someone on our team raised the question "should we build our own harness?" the answer was the same: there are five excellent ones, pick one.
We picked one. Then another. Then a third. Each attempt looked reasonable on Monday and broke on Friday. By the end of the third try the question reframed itself. It was no longer "should we build our own harness?". It was "are we willing to ship a team-scale coordination product on top of someone else's choreography?".
We were not. So we built our own.
Other companies in this space have written about why they built their own harnesses, and we've read those posts carefully. Their reasoning typically runs from the bottom up: they needed control over the runtime to ship a great agent. Ours runs in the opposite direction: we needed control over the runtime to ship a great team layer. Same word, different floor. This post is about the floor we built, what it deliberately refuses to do, and what we think it means for the next generation of software consulting and services companies.
01. What a harness actually is
The harness is the runtime between intent and execution. It is not the model. It is not the IDE. It is not the spec format. It is the choreography layer that turns "do this thing" into a sequence of tool calls, prompts, retrievals, sandbox runs, evidence captures, error recoveries, retries, and telemetry.
Every agent has one. Usually it is invisible. Claude Code's harness is the part that decides which tools to call, when to read, when to edit, when to run a test, and how to recover when a step fails. Cursor's is the part that decomposes "fix this bug" into a multi-file plan and walks through it. Devin's is the part that runs in a VM, opens a browser, drives a terminal, and routes between them. These harnesses are good. They are also opinionated, in ways the agent literature glosses over.
If you are building on top of an agent, you inherit its harness. That means you inherit:
- The spec format the harness can ingest cleanly
- The tool surface the harness exposes (what's a "step", what's an "evidence", what's a "retry")
- The review shape that comes back at the end (a diff, a trace, a report)
- The logging schema the harness emits
- The failure modes that bubble up vs. the ones that get swallowed
- The concurrency model (one task, many tasks, parallel agents, sequential)
Most of these decisions look like implementation details. They are not. They are the shape of every workflow downstream. And once your team has built around a vendor's harness, that harness becomes the load-bearing layer of your operation, whether you intended it to be or not.
02. Why we tried three times before building our own
It is worth being concrete about what broke.
Attempt one: wrap Claude Code as the runtime. We treated Claude Code as our agent and put a thin coordination shim above it. It worked great for one developer running one task. It broke the moment we tried to run two specs against the same repo with different agents. The harness assumed it owned the workspace. We did not. When we tried to share workspace state between agents, the assumptions Claude Code's harness made about file locks, branch state, and tool availability did not survive contact with multi-agent reality. Fine for solo work. Wrong shape for a team substrate.
Attempt two: sit on top of Cursor's agent mode. Cursor's harness has a beautiful single-developer experience. It also has an IDE in the middle of it. Our use case did not need an IDE. We needed headless execution from CI, from a Slack command, from a scheduled cron, from a GitHub webhook. Every time we tried to invoke Cursor's agent without the editor in the loop we hit a wall. The harness was designed to be an editing surface. We were trying to make it a server. That is not what it is for, and the seams showed within a week.
Attempt three: use Devin's API as the executor. Devin's harness lives in Cognition's cloud. Clean API, well-designed task model. It broke us in two ways. The first was operational: every task ran in Cognition's environment, which meant our customers' code was crossing a boundary they had not agreed to. The second was architectural: we could not swap models per task. SWE-1.6 today, Opus 4.7 tomorrow, Kimi the week after, all with the same spec. That is the entire premise. Devin's harness picks the model. We needed to pick the model.
Three attempts, three reasonable products, three wrong shapes for what we were trying to do. The pattern was consistent. Every off-the-shelf harness was excellent for the workflow it was designed for, and broken for the one we needed.
A harness is not a neutral runtime. It is a set of opinions about what work looks like. When those opinions match your workflow, the harness disappears. When they don't, you spend more time fighting it than using it, and you don't notice until the second quarter.
03. What we built
Steerdev's harness has a strict scope. It is the runtime between a versioned spec and an executing agent. Inside that scope it does six things and refuses to do anything else.
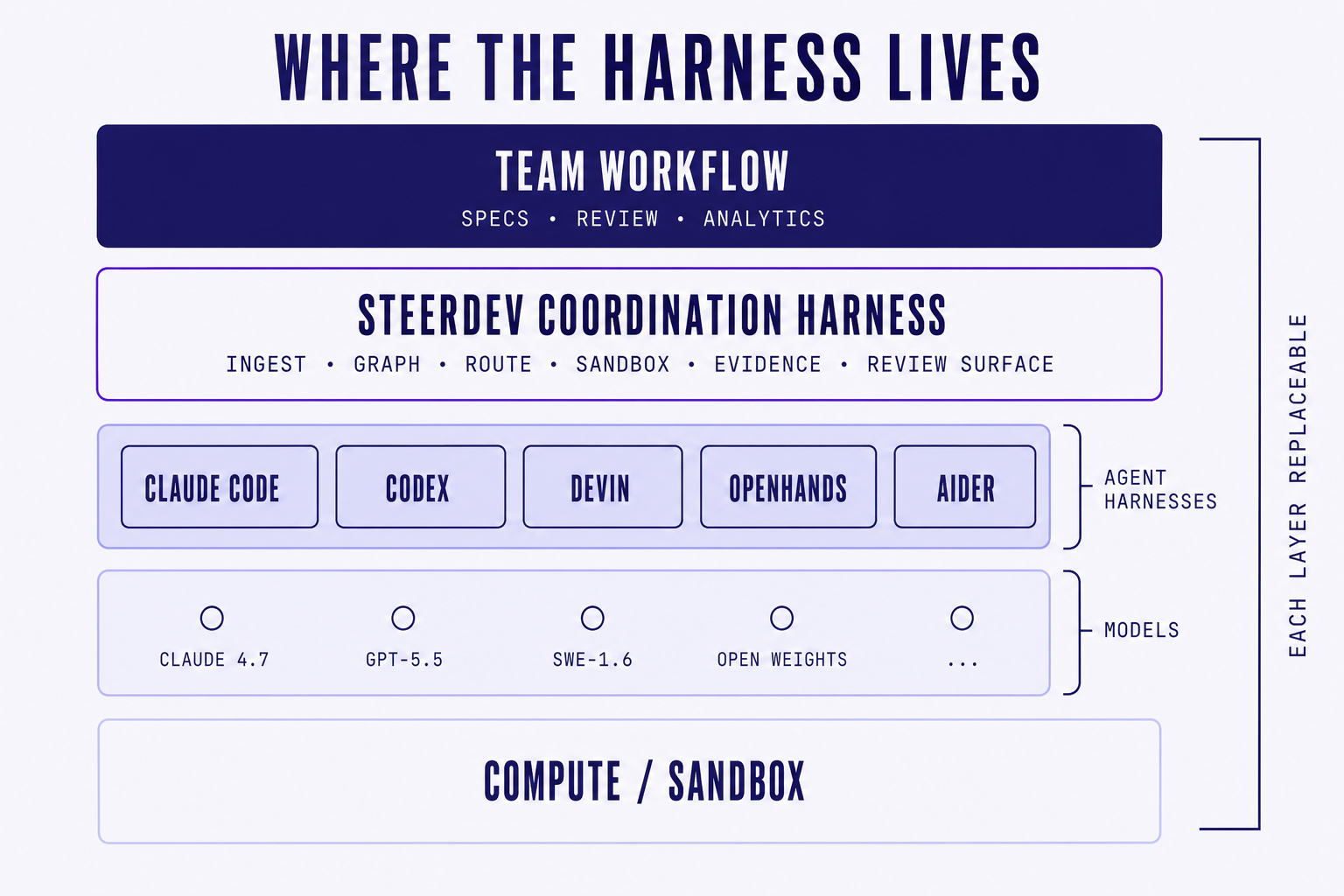
It does this:
Spec ingestion. Specs are plain Markdown with structured sections. Acceptance criteria, dependencies, owner, scope. The harness parses, validates, and turns the spec into a task graph. No proprietary schema. No
.steerdev/specs/directory format you can't read in any other tool. If a human can review it, an agent can run it.Task graph construction. The harness decomposes the spec into a directed graph of tasks, each with file-level dependency hints, expected evidence, and a routing policy. Waves are computed automatically. Tasks that would collide on shared files are scheduled in sequence. Tasks that are independent run in parallel.
Agent routing. Every task carries a routing policy: which agent runtime to use, which model, which cost tier, which fallback if the first run fails. Claude Code for the dense backend pass. Codex for the frontend component refactor. A self-hosted OpenHands cluster for the long migration script. A cheap open-weight model for the ten thousand boilerplate edits. The harness picks the runtime per task, not per project.
Execution sandboxing. Every agent runs in an isolated workspace. File-system snapshots are taken before and after. Branches are managed by the harness, not the agent. No agent has direct access to the canonical repository state. All changes come back through diffs the harness can verify.
Evidence collection. Every run produces structured evidence: tests run, tests passed, files touched, lines changed, time elapsed, model used, cost incurred, failures encountered, retries triggered. The schema is the same regardless of which agent ran the task. That is the part that makes the analytics layer above the harness possible at all.
Review surface. The spec, the diff, the evidence, and the agent trace all sit next to each other. Reviewers see what the spec asked, what the agent shipped, and which acceptance criteria the evidence covers. Review is comparison, not interpretation.
It does not do this:
- It does not generate code. That is the agent's job.
- It does not pick a model. That is a routing policy you write, not a default we hand you.
- It does not own the IDE. You can run any editor on top of it.
- It does not own the agent. You swap them like you swap models.
- It does not own the cloud. Every component can be self-hosted.
- It does not replace the developer. Specs are written by humans. Reviews are signed off by humans. Judgment lives in the team.
The line we hold is unfashionable. Every other vendor in this space is moving up the stack to do more. We are doing less, on purpose. The harness is choreography. The agents are dancers. The team is choreographer and audience at the same time. Our job is to make sure the dancers know the steps and the audience can see the show.
04. What model-agnostic actually means at the harness layer
Most vendors mean "we route to multiple models" when they say agent-agnostic. That is table-stakes multi-model routing and it does not solve the real problem. Multi-model routing is choosing which LLM sits behind one harness. Agent-agnostic, the way we mean it, is choosing which entire harness sits behind one spec.
Claude Code is not just Claude. It is Claude plus a harness that decides what tools to call, what to evidence, what to retry. Codex is not just GPT. It is GPT plus a different harness with different defaults. When you swap from one to the other you are not just swapping a model. You are swapping a runtime. The spec format that worked for one will not work for the other unless something above both of them is normalizing the contract.
That something is what we built.
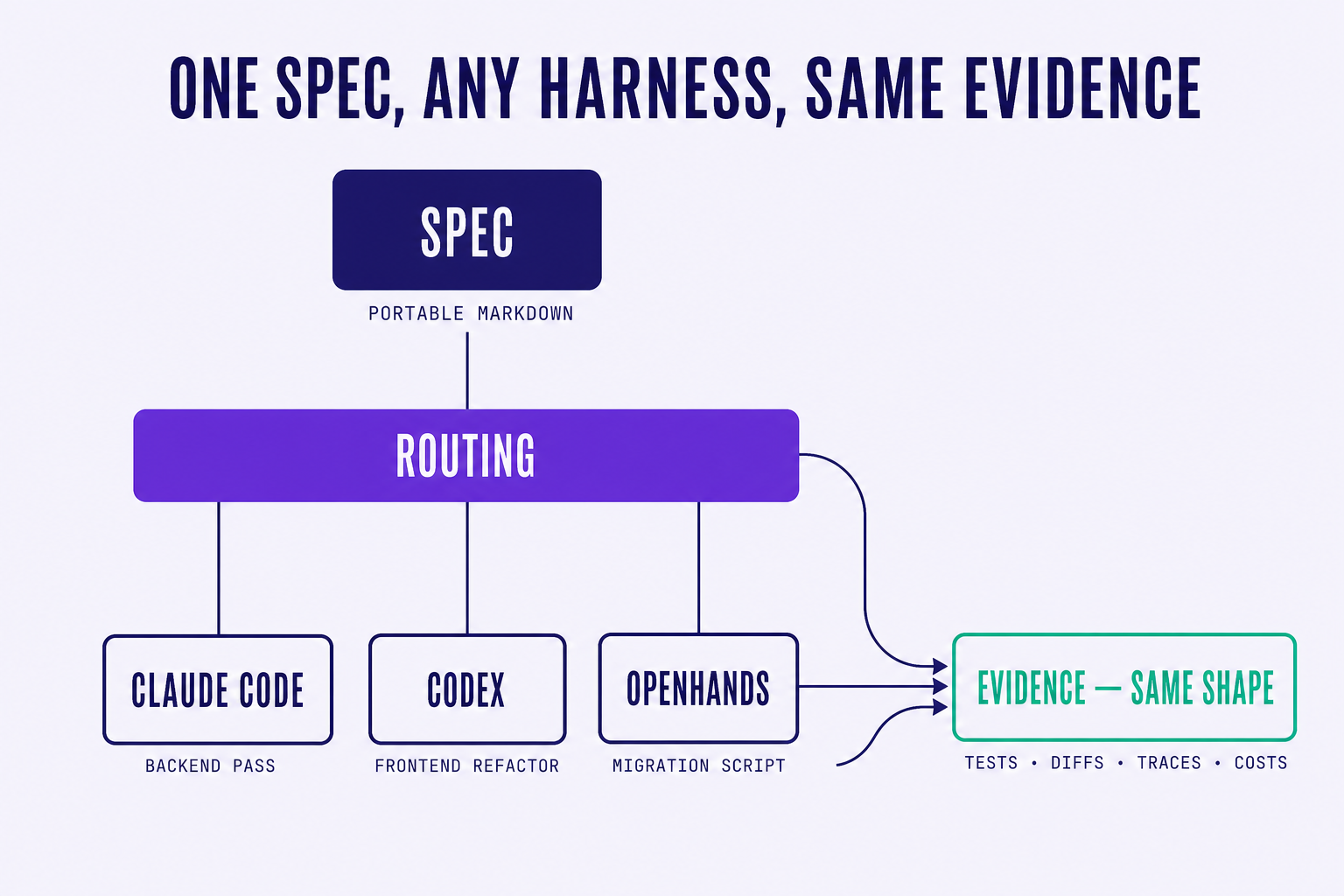
A thin, opinionated coordination layer that takes a portable spec and routes it to whichever harness underneath does the best job for that task today. Claude Code, Codex, OpenHands, Aider, Devin's API when the operational shape works for our customers, a self-hosted runtime when the workload is regulated. The spec does not change. The review surface does not change. The analytics do not change. Only the executing harness changes, per task.
The test we use internally is the one we keep coming back to: if a better harness ships next Thursday, can we route the next task to it without rewriting any spec, any review template, or any dashboard? If the answer is yes, our harness is doing its job. If the answer is "well, mostly, except for X and Y", we have lock-in we have not yet refactored out, and we file a bug against ourselves.
05. Why the floor matters
Every layer of an agent-driven engineering stack rests on the harness underneath it. The spec layer assumes the harness can ingest specs. The review layer assumes the harness emits evidence in a known shape. The analytics layer assumes the harness reports tasks, runs, models, and costs in a normalized schema. The team layer assumes the harness can run in headless mode, on a schedule, from a webhook, from a Slack command, from a GitHub action, from a developer's terminal, all the same way.
If the harness moves, every layer above it cracks. That is what we lived through during the three failed attempts. We would build a beautiful spec view, then have to rewrite it when Claude Code changed its evidence format. We would ship a review interface, then watch it break when Cursor's agent mode reshaped its tool calls. We would build an analytics dashboard, then realize half the metrics we needed were not exposed at all by the upstream API.
The harness is the floor. If the floor moves, everything cracks.
"We used to ship a feature in three weeks and rebuild our internal tooling for two more weeks every time our agent vendor pushed a release. Now we ship features and the vendor's release is something the harness routes around. That is the difference." Principal Engineer, fintech infrastructure team
Building this was a longer project than we wanted. Shipping a coordination layer on top of someone else's harness would have been faster for the first six months and impossible for the next eighteen. We made the trade once. We will not make it again.
06. The harness is temporary, the layer above it is permanent
We said this in a different post a few weeks ago, and it applies again here1. The agent you use today is a temporary choice. The harness underneath the agent is, increasingly, a temporary choice too (vendors ship weekly, regress sometimes, get bought, pivot). The only permanent thing in this stack is the layer your team builds on top of all of that. Specs, reviews, analytics, the contract between humans and machines for what "shipped" means.
The layer above the harness has to be permanent. The harness underneath it has to be ours. Those two requirements together explain almost everything about what Steerdev is and is not. We are the floor and the ceiling. The agents are the elevator. The elevator changes. The building does not.
This is our view on where software consulting and services companies are heading. The ones that survive the next cycle will not be the ones with the best agent of the month. They will be the ones who own the coordination layer their teams actually run on: the floor underneath the specs, the reviews, the analytics, the contract with their customers about what "shipped" means. Everything else, including the agent, is a tenant.
Thanks for reading this blog! If you are evaluating where your team's coordination layer should live, ask the question we wish we had asked sooner: is the floor under our specs something we control, or something a vendor controls for us? The answer to that question shapes the next two years of your engineering org (and, if you run a services company, your next two years of margin). We built our own harness because the only acceptable answer was the first one. You can borrow ours, or build yours, or stay on someone else's. Just know which one you are doing, and what cracks the day the floor moves.
References
- Steerdev, Agent-Agnostic Is the Only Sane Default, May 2026.
- Anthropic, Claude Code on GitHub, the agentic CLI whose harness we wrapped first.
- Cognition, Introducing Devin, the cloud-resident harness referenced in attempt three.
- Kiro, Bring engineering rigor to agentic development, spec-first harness from AWS.
References
-
Agent-Agnostic Is the Only Sane Default (and Here's the Data to Prove It), Steerdev, May 2026. ↩


